[ Upstream commit 48856286b6 ]
A buggy or malicious frontend should not be able to confuse netback.
If we spot anything which is not as it should be then shutdown the
device and don't try to continue with the ring in a potentially
hostile state. Well behaved and non-hostile frontends will not be
penalised.
As well as making the existing checks for such errors fatal also add a
new check that ensures that there isn't an insane number of requests
on the ring (i.e. more than would fit in the ring). If the ring
contains garbage then previously is was possible to loop over this
insane number, getting an error each time and therefore not generating
any more pending requests and therefore not exiting the loop in
xen_netbk_tx_build_gops for an externded period.
Also turn various netdev_dbg calls which no precipitate a fatal error
into netdev_err, they are rate limited because the device is shutdown
afterwards.
This fixes at least one known DoS/softlockup of the backend domain.
Signed-off-by: Ian Campbell <ian.campbell@citrix.com>
Reviewed-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Acked-by: Jan Beulich <JBeulich@suse.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit daf3ec688e ]
TG3_PHY_AUXCTL_SMDSP_ENABLE/DISABLE macros do a blind write to the phy
auxiliary control register and overwrite the EXT_PKT_LEN (bit 14) resulting
in intermittent crc errors on jumbo frames with some link partners. Change
the code to do a read/modify/write.
Signed-off-by: Nithin Nayak Sujir <nsujir@broadcom.com>
Signed-off-by: Michael Chan <mchan@broadcom.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 9c13cb8bb4 ]
When netconsole is enabled, logging messages generated during tg3_open
can result in a null pointer dereference for the uninitialized tg3
status block. Use the irq_sync flag to disable polling in the early
stages. irq_sync is cleared when the driver is enabling interrupts after
all initialization is completed.
Signed-off-by: Nithin Nayak Sujir <nsujir@broadcom.com>
Signed-off-by: Michael Chan <mchan@broadcom.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 794ed393b7 ]
Ben Greear reported crashes in ip_rcv_finish() on a stress
test involving many macvlans.
We tracked the bug to a dst use after free. ip_rcv_finish()
was calling dst->input() and got garbage for dst->input value.
It appears the bug is in loopback driver, lacking
a skb_dst_force() before calling netif_rx().
As a result, a non refcounted dst, normally protected by a
RCU read_lock section, was escaping this section and could
be freed before the packet being processed.
[<ffffffff813a3c4d>] loopback_xmit+0x64/0x83
[<ffffffff81477364>] dev_hard_start_xmit+0x26c/0x35e
[<ffffffff8147771a>] dev_queue_xmit+0x2c4/0x37c
[<ffffffff81477456>] ? dev_hard_start_xmit+0x35e/0x35e
[<ffffffff8148cfa6>] ? eth_header+0x28/0xb6
[<ffffffff81480f09>] neigh_resolve_output+0x176/0x1a7
[<ffffffff814ad835>] ip_finish_output2+0x297/0x30d
[<ffffffff814ad6d5>] ? ip_finish_output2+0x137/0x30d
[<ffffffff814ad90e>] ip_finish_output+0x63/0x68
[<ffffffff814ae412>] ip_output+0x61/0x67
[<ffffffff814ab904>] dst_output+0x17/0x1b
[<ffffffff814adb6d>] ip_local_out+0x1e/0x23
[<ffffffff814ae1c4>] ip_queue_xmit+0x315/0x353
[<ffffffff814adeaf>] ? ip_send_unicast_reply+0x2cc/0x2cc
[<ffffffff814c018f>] tcp_transmit_skb+0x7ca/0x80b
[<ffffffff814c3571>] tcp_connect+0x53c/0x587
[<ffffffff810c2f0c>] ? getnstimeofday+0x44/0x7d
[<ffffffff810c2f56>] ? ktime_get_real+0x11/0x3e
[<ffffffff814c6f9b>] tcp_v4_connect+0x3c2/0x431
[<ffffffff814d6913>] __inet_stream_connect+0x84/0x287
[<ffffffff814d6b38>] ? inet_stream_connect+0x22/0x49
[<ffffffff8108d695>] ? _local_bh_enable_ip+0x84/0x9f
[<ffffffff8108d6c8>] ? local_bh_enable+0xd/0x11
[<ffffffff8146763c>] ? lock_sock_nested+0x6e/0x79
[<ffffffff814d6b38>] ? inet_stream_connect+0x22/0x49
[<ffffffff814d6b49>] inet_stream_connect+0x33/0x49
[<ffffffff814632c6>] sys_connect+0x75/0x98
This bug was introduced in linux-2.6.35, in commit
7fee226ad2 (net: add a noref bit on skb dst)
skb_dst_force() is enforced in dev_queue_xmit() for devices having a
qdisc.
Reported-by: Ben Greear <greearb@candelatech.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Tested-by: Ben Greear <greearb@candelatech.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 5d0feaff23 ]
This was introduced in commit 6dccd16 "r8169: merge with version
6.001.00 of Realtek's r8169 driver". I did not find the version
6.001.00 online, but in 6.002.00 or any later r8169 from Realtek
this hunk is no longer present.
Also commit 05af214 "r8169: fix Ethernet Hangup for RTL8110SC
rev d" claims to have fixed this issue otherwise.
The magic compare mask of 0xfffe000 is dubious as it masks
parts of the Reserved part, and parts of the VLAN tag. But this
does not make much sense as the VLAN tag parts are perfectly
valid there. In matter of fact this seems to be triggered with
any VLAN tagged packet as RxVlanTag bit is matched. I would
suspect 0xfffe0000 was intended to test reserved part only.
Finally, this hunk is evil as it can cause more packets to be
handled than what was NAPI quota causing net/core/dev.c:
net_rx_action(): WARN_ON_ONCE(work > weight) to trigger, and
mess up the NAPI state causing device to hang.
As result, any system using VLANs and having high receive
traffic (so that NAPI poll budget limits rtl_rx) would result
in device hang.
Signed-off-by: Timo Teräs <timo.teras@iki.fi>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 1adb2e2b5f upstream.
When the next beacon is sent, the ath_buf from the previous run is reused.
If getting a new beacon from mac80211 fails, bf->bf_mpdu is not reset, yet
the skb is freed, leading to a double-free on the next beacon tx attempt,
resulting in a system crash.
Signed-off-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit ee50e135ae upstream.
Errors in CAN protocol (location) are reported in data[3] of the can
frame instead of data[2].
Signed-off-by: Olivier Sobrie <olivier@sobrie.be>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 9c170e0686 upstream.
This reverts commit f74b9d365d.
Turns out reverting commit a240dc7b3c
"ath9k_hw: Updated AR9003 tx gain table for 5GHz" was not enough to
bring the tx power back to normal levels on devices like the
Buffalo WZR-HP-G450H, this one needs to be reverted as well.
This revert improves tx power by ~10 db on that device
Signed-off-by: Felix Fietkau <nbd@openwrt.org>
Cc: rmanohar@qca.qualcomm.com
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit ab48b03ec9 upstream.
If the restart timer is running due to BUS-OFF and the device is
disconnected an dev_put will decrease the usage counter to -1 thus
blocking the interface removal, resulting in the following dmesg
lines repeating every 10s:
can: notifier: receive list not found for dev can0
can: notifier: receive list not found for dev can0
can: notifier: receive list not found for dev can0
unregister_netdevice: waiting for can0 to become free. Usage count = -1
Signed-off-by: Alexander Stein <alexander.stein@systec-electronic.com>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit e196c0e579 ]
Race between bonding_store_slaves_active() and slave manipulation
functions. The bond_for_each_slave use in bonding_store_slaves_active()
is not protected by any synchronization mechanism.
NULL pointer dereference is easy to reach.
Fixed by acquiring the bond->lock for the slave walk.
v2: Make description text < 75 columns
Signed-off-by: Nikolay Aleksandrov <nikolay@redhat.com>
Signed-off-by: Jay Vosburgh <fubar@us.ibm.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit dd321acddc upstream.
When host_sleep_config command fails we should return error to
MMC core to indicate the failure for our device.
The misspelled variable is also removed as it's redundant.
Signed-off-by: Bing Zhao <bzhao@marvell.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit aee77e4acc upstream.
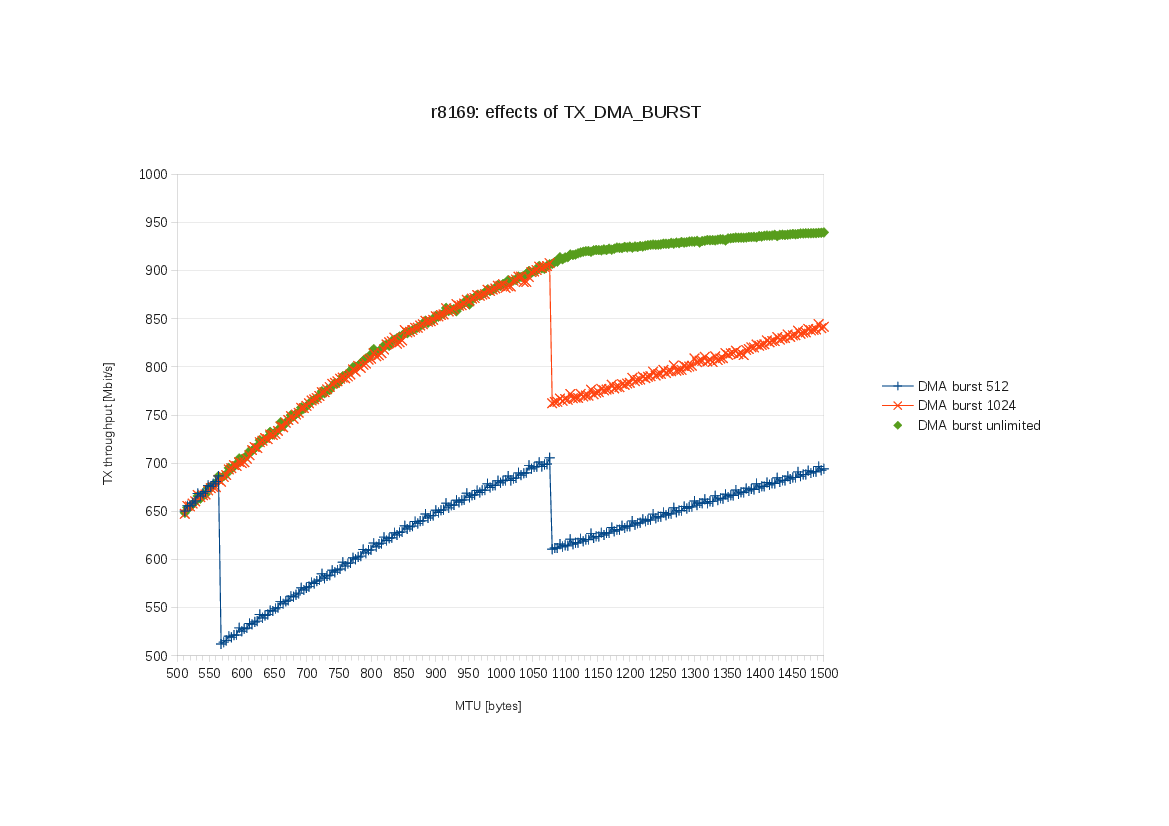
The r8169 driver currently limits the DMA burst for TX to 1024 bytes. I have
a box where this prevents the interface from using the gigabit line to its full
potential. This patch solves the problem by setting TX_DMA_BURST to unlimited.
The box has an ASRock B75M motherboard with on-board RTL8168evl/8111evl
(XID 0c900880). TSO is enabled.
I used netperf (TCP_STREAM test) to measure the dependency of TX throughput
on MTU. I did it for three different values of TX_DMA_BURST ('5'=512, '6'=1024,
'7'=unlimited). This chart shows the results:
http://michich.fedorapeople.org/r8169/r8169-effects-of-TX_DMA_BURST.png
Interesting points:
- With the current DMA burst limit (1024):
- at the default MTU=1500 I get only 842 Mbit/s.
- when going from small MTU, the performance rises monotonically with
increasing MTU only up to a peak at MTU=1076 (908 MBit/s). Then there's
a sudden drop to 762 MBit/s from which the throughput rises monotonically
again with further MTU increases.
- With a smaller DMA burst limit (512):
- there's a similar peak at MTU=1076 and another one at MTU=564.
- With unlimited DMA burst:
- at the default MTU=1500 I get nice 940 Mbit/s.
- the throughput rises monotonically with increasing MTU with no strange
peaks.
Notice that the peaks occur at MTU sizes that are multiples of the DMA burst
limit plus 52. Why 52? Because:
20 (IP header) + 20 (TCP header) + 12 (TCP options) = 52
The Realtek-provided r8168 driver (v8.032.00) uses unlimited TX DMA burst too,
except for CFG_METHOD_1 where the TX DMA burst is set to 512 bytes.
CFG_METHOD_1 appears to be the oldest MAC version of "RTL8168B/8111B",
i.e. RTL_GIGA_MAC_VER_11 in r8169. Not sure if this MAC version really needs
the smaller burst limit, or if any other versions have similar requirements.
Signed-off-by: Michal Schmidt <mschmidt@redhat.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 39707c2a3b ]
Driver anchors the tx urbs and defers the urb submission if
a transmit request comes when the interface is suspended.
Anchoring urb increments the urb reference count. These
deferred urbs are later accessed by calling usb_get_from_anchor()
for submission during interface resume. usb_get_from_anchor()
unanchors the urb but urb reference count remains same.
This causes the urb reference count to remain non-zero
after usb_free_urb() gets called and urb never gets freed.
Hence call usb_put_urb() after anchoring the urb to properly
balance the reference count for these deferred urbs. Also,
unanchor these deferred urbs during disconnect, to free them
up.
Signed-off-by: Hemant Kumar <hemantk@codeaurora.org>
Acked-by: Oliver Neukum <oneukum@suse.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit bf7e1abe43 upstream.
Some hardware has correct (!= 0xff) value of tssi_bounds[4] in the
EEPROM, but step is equal to 0xff. This results on ridiculous delta
calculations and completely broke TX power settings.
Reported-and-tested-by: Pavel Lucik <pavel.lucik@gmail.com>
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Acked-by: Ivo van Doorn <IvDoorn@gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 8c6e30936a upstream.
bf->bf_next is only while buffers are chained as part of an A-MPDU
in the tx queue. When a tid queue is flushed (e.g. on tearing down
an aggregation session), frames can be enqueued again as normal
transmission, without bf_next being cleared. This can lead to the
old pointer being dereferenced again later.
This patch might fix crashes and "Failed to stop TX DMA!" messages.
Signed-off-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit ad1be8d345 upstream.
When register_netdev fails, the init'ed NAPIs by netif_napi_add must be
deleted with netif_napi_del, and also when driver unloads, it should
delete the NAPI before unregistering netdevice using unregister_netdev.
Signed-off-by: Devendra Naga <devendra.aaru@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 477206a018 upstream.
The r8169 may get stuck or show bad behaviour after activating TSO :
the net_device is not stopped when it has no more TX descriptors.
This problem comes from TX_BUFS_AVAIL which may reach -1 when all
transmit descriptors are in use. The patch simply tries to keep positive
values.
Tested with 8111d(onboard) on a D510MO, and with 8111e(onboard) on a
Zotac 890GXITX.
Signed-off-by: Julien Ducourthial <jducourt@free.fr>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 2a15cd2ff4 upstream.
With runtime PM, if the ethernet cable is disconnected, the device is
transitioned to D3 state to conserve energy. If the system is shutdown
in this state, any register accesses in rtl_shutdown are dropped on
the floor. As the device was programmed by .runtime_suspend() to wake
on link changes, it is thus brought back up as soon as the link recovers.
Resuming every suspended device through the driver core would slow things
down and it is not clear how many devices really need it now.
Original report and D0 transition patch by Sameer Nanda. Patch has been
changed to comply with advices by Rafael J. Wysocki and the PM folks.
Reported-by: Sameer Nanda <snanda@chromium.org>
Signed-off-by: Francois Romieu <romieu@fr.zoreil.com>
Cc: Rafael J. Wysocki <rjw@sisk.pl>
Cc: Hayes Wang <hayeswang@realtek.com>
Cc: Alan Stern <stern@rowland.harvard.edu>
Acked-by: Rafael J. Wysocki <rjw@sisk.pl>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 811fd3010c upstream.
Realtek has specified that the post 8168c gigabit chips and the post
8105e fast ethernet chips recover automatically from a Rx FIFO overflow.
The driver does not need to clear the RxFIFOOver bit of IntrStatus and
it should rather avoid messing it.
The implementation deserves some explanation:
1. events outside of the intr_event bit mask are now ignored. It enforces
a no-processing policy for the events that either should not be there
or should be ignored.
2. RxFIFOOver was already ignored in rtl_cfg_infos[RTL_CFG_1] for the
whole 8168 line of chips with two exceptions:
- RTL_GIGA_MAC_VER_22 since b5ba6d12bd
("use RxFIFO overflow workaround for 8168c chipset.").
This one should now be correctly handled.
- RTL_GIGA_MAC_VER_11 (8168b) which requires a different Rx FIFO
overflow processing.
Though it does not conform to Realtek suggestion above, the updated
driver includes no change for RTL_GIGA_MAC_VER_12 and RTL_GIGA_MAC_VER_17.
Both are 8168b. RTL_GIGA_MAC_VER_12 is common and a bit old so I'd rather
wait for experimental evidence that the change suggested by Realtek really
helps or does not hurt in unexpected ways.
Removed case statements in rtl8169_interrupt are only 8168 relevant.
3. RxFIFOOver is masked for post 8105e 810x chips, namely the sole 8105e
(RTL_GIGA_MAC_VER_30) itself.
Signed-off-by: Francois Romieu <romieu@fr.zoreil.com>
Cc: hayeswang <hayeswang@realtek.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Reviewed-by: Jonathan Nieder <jrnieder@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 10953db8e1 upstream
The link down would occur when reseting PHY. And it would take about 2 ~ 5
seconds from link down to link up. If the delay of pm_schedule_suspend is
not long enough, the device would enter runtime_suspend before link up.
After link up, the device would wake up and reset PHY again. Then, you
would find the driver keep in a loop of runtime_suspend and rumtime_resume.
Signed-off-by: Hayes Wang <hayeswang@realtek.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit deb9d93c89 upstream.
8168d and above allow jumbo frames beyond 8k. Bump the received
packet length check before enabling jumbo frames on these chipsets.
Frame length indication covers bits 0..13 of the first Rx descriptor
32 bits for the 8169 and 8168. I only have authoritative documentation
for the allowed use of the extra (13) bit with the 8169 and 8168c.
Realtek's drivers use the same mask for the 816x and the fast ethernet
only 810x.
Signed-off-by: Francois Romieu <romieu@fr.zoreil.com>
Acked-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit d58d46b5d8 upstream.
- fix features : jumbo frames and checksumming can not be used at the
same time.
- introduce hw_jumbo_{enable / disable} helpers. Their content has been
creatively extracted from Realtek's own drivers. As an illustration,
it would be nice to know how/if the MaxTxPacketSize register operates
when the device can work with a 9k jumbo frame as its documentation
(8168c) can not be applied beyond ~7k.
- rtl_tx_performance_tweak is moved forward. No change.
Signed-off-by: Francois Romieu <romieu@fr.zoreil.com>
Acked-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
{kind=link}