commit 47ea91b405 upstream.
__find_resource() incorrectly returns a resource window which overlaps
an existing allocated window. This happens when the parent's
resource-window spans 0x00000000 to 0xffffffff and is entirely allocated
to all its children resource-windows.
__find_resource() looks for gaps in resource allocation among the
children resource windows. When it encounters the last child window it
blindly tries the range next to one allocated to the last child. Since
the last child's window ends at 0xffffffff the calculation overflows,
leading the algorithm to believe that any window in the range 0x0000000
to 0xfffffff is available for allocation. This leads to a conflicting
window allocation.
Michal Ludvig reported this issue seen on his platform. The following
patch fixes the problem and has been verified by Michal. I believe this
bug has been there for ages. It got exposed by git commit 2bbc694227
("PCI : ability to relocate assigned pci-resources")
Signed-off-by: Ram Pai <linuxram@us.ibm.com>
Tested-by: Michal Ludvig <mludvig@logix.net.nz>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Herton Ronaldo Krzesinski <herton.krzesinski@canonical.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit a4ac9fea01 upstream.
During debug of one SRIOV enabled hotplug device, we found found that
add_size is not passed properly.
The device has devices under two level bridges:
+-[0000:80]-+-00.0-[81-8f]--
| +-01.0-[90-9f]--
| +-02.0-[a0-af]----00.0-[a1-a3]--+-02.0-[a2]--+-00.0 Oracle Corporation Device
| | \-03.0-[a3]--+-00.0 Oracle Corporation Device
Which means later the parent bridge will not try to add a big enough range:
[ 557.455077] pci 0000:a0:00.0: BAR 14: assigned [mem 0xf9000000-0xf93fffff]
[ 557.461974] pci 0000:a0:00.0: BAR 15: assigned [mem 0xf6000000-0xf61fffff pref]
[ 557.469340] pci 0000:a1:02.0: BAR 14: assigned [mem 0xf9000000-0xf91fffff]
[ 557.476231] pci 0000:a1:02.0: BAR 15: assigned [mem 0xf6000000-0xf60fffff pref]
[ 557.483582] pci 0000:a1:03.0: BAR 14: assigned [mem 0xf9200000-0xf93fffff]
[ 557.490468] pci 0000:a1:03.0: BAR 15: assigned [mem 0xf6100000-0xf61fffff pref]
[ 557.497833] pci 0000:a1:03.0: BAR 14: can't assign mem (size 0x200000)
[ 557.504378] pci 0000:a1:03.0: failed to add optional resources res=[mem 0xf9200000-0xf93fffff]
[ 557.513026] pci 0000:a1:02.0: BAR 14: can't assign mem (size 0x200000)
[ 557.519578] pci 0000:a1:02.0: failed to add optional resources res=[mem 0xf9000000-0xf91fffff]
It turns out we did not calculate size1 properly.
static resource_size_t calculate_memsize(resource_size_t size,
resource_size_t min_size,
resource_size_t size1,
resource_size_t old_size,
resource_size_t align)
{
if (size < min_size)
size = min_size;
if (old_size == 1 )
old_size = 0;
if (size < old_size)
size = old_size;
size = ALIGN(size + size1, align);
return size;
}
We should not pass add_size with min_size in calculate_memsize since
that will make add_size not contribute final add_size.
So just pass add_size with size1 to calculate_memsize().
With this change, we should have chance to remove extra addon in
pci_reassign_resource.
Signed-off-by: Yinghai Lu <yinghai@kernel.org>
Signed-off-by: Jesse Barnes <jbarnes@virtuousgeek.org>
Cc: Andrew Worsley <amworsley@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 2bbc694227 upstream.
Currently pci-bridges are allocated enough resources to satisfy their immediate
requirements. Any additional resource-requests fail if additional free space,
contiguous to the one already allocated, is not available. This behavior is not
reasonable since sufficient contiguous resources, that can satisfy the request,
are available at a different location.
This patch provides the ability to expand and relocate a allocated resource.
v2: Changelog: Fixed size calculation in pci_reassign_resource()
v3: Changelog : Split this patch. The resource.c changes are already
upstream. All the pci driver changes are in here.
Signed-off-by: Ram Pai <linuxram@us.ibm.com>
Signed-off-by: Jesse Barnes <jbarnes@virtuousgeek.org>
Cc: Andrew Worsley <amworsley@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 361d94a338 upstream.
Calls into reiserfs journalling code and reiserfs_get_block() need to
be protected with write lock. We remove write lock around calls to high
level quota code in the next patch so these paths would suddently become
unprotected.
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 7af1168693 upstream.
Calls into highlevel quota code cannot happen under the write lock. These
calls take dqio_mutex which ranks above write lock. So drop write lock
before calling back into quota code.
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b9e06ef2e8 upstream.
In reiserfs_quota_on() we do quite some work - for example unpacking
tail of a quota file. Thus we have to hold write lock until a moment
we call back into the quota code.
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3bb3e1fc47 upstream.
When remounting reiserfs dquot_suspend() or dquot_resume() can be called.
These functions take dqonoff_mutex which ranks above write lock so we have
to drop it before calling into quota code.
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 399f11c3d8 upstream.
Currently, we will schedule session recovery and then return to the
caller of nfs4_handle_exception. This works for most cases, but causes
a hang on the following test case:
Client Server
------ ------
Open file over NFS v4.1
Write to file
Expire client
Try to lock file
The server will return NFS4ERR_BADSESSION, prompting the client to
schedule recovery. However, the client will continue placing lock
attempts and the open recovery never seems to be scheduled. The
simplest solution is to wait for session recovery to run before retrying
the lock.
Signed-off-by: Bryan Schumaker <bjschuma@netapp.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit a9193983f4 upstream.
The overlay on the i830M has a peculiar failure mode: It works the
first time around after boot-up, but consistenly hangs the second time
it's used.
Chris Wilson has dug out a nice errata:
"1.5.12 Clock Gating Disable for Display Register
Address Offset: 06200h–06203h
"Bit 3
Ovrunit Clock Gating Disable.
0 = Clock gating controlled by unit enabling logic
1 = Disable clock gating function
DevALM Errata ALM049: Overlay Clock Gating Must be Disabled: Overlay
& L2 Cache clock gating must be disabled in order to prevent device
hangs when turning off overlay.SW must turn off Ovrunit clock gating
(6200h) and L2 Cache clock gating (C8h)."
Now I've nowhere found that 0xc8 register and hence couldn't apply the
l2 cache workaround. But I've remembered that part of the magic that
the OVERLAY_ON/OFF commands are supposed to do is to rearrange cache
allocations so that the overlay scaler has some scratch space.
And while pondering how that could explain the hang the 2nd time we
enable the overlay, I've remembered that the old ums overlay code did
_not_ issue the OVERLAY_OFF cmd.
And indeed, disabling the OFF cmd results in the overlay working
flawlessly, so I guess we can workaround the lack of the above
workaround by simply never disabling the overlay engine once it's
enabled.
Note that we have the first part of the above w/a already implemented
in i830_init_clock_gating - leave that as-is to avoid surprises.
v2: Add a comment in the code.
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=47827
Tested-by: Rhys <rhyspuk@gmail.com>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2:
- Adjust context
- s/intel_ring_emit(ring, /OUT_RING(/]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 069ddcda37 upstream.
When the eCryptfs mount options do not include '-o acl', but the lower
filesystem's mount options do include 'acl', the MS_POSIXACL flag is not
flipped on in the eCryptfs super block flags. This flag is what the VFS
checks in do_last() when deciding if the current umask should be applied
to a newly created inode's mode or not. When a default POSIX ACL mask is
set on a directory, the current umask is incorrectly applied to new
inodes created in the directory. This patch ignores the MS_POSIXACL flag
passed into ecryptfs_mount() and sets the flag on the eCryptfs super
block depending on the flag's presence on the lower super block.
Additionally, it is incorrect to allow a writeable eCryptfs mount on top
of a read-only lower mount. This missing check did not allow writes to
the read-only lower mount because permissions checks are still performed
on the lower filesystem's objects but it is best to simply not allow a
rw mount on top of ro mount. However, a ro eCryptfs mount on top of a rw
mount is valid and still allowed.
https://launchpad.net/bugs/1009207
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Reported-by: Stefan Beller <stefanbeller@googlemail.com>
Cc: John Johansen <john.johansen@canonical.com>
Cc: Herton Ronaldo Krzesinski <herton.krzesinski@canonical.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 0658a3366d upstream.
The use of kfree(serial) in error cases of usb_serial_probe
was invalid - usb_serial structure allocated in create_serial()
gets reference of usb_device that needs to be put, so we need
to use usb_serial_put() instead of simple kfree().
Signed-off-by: Jan Safrata <jan.nikitenko@gmail.com>
Acked-by: Johan Hovold <jhovold@gmail.com>
Cc: Richard Retanubun <richardretanubun@ruggedcom.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 38fe36a248 upstream.
ICMP tuples have id in src and type/code in dst.
So comparing src.u.all with dst.u.all will always fail here
and ip_xfrm_me_harder() is called for every ICMP packet,
even if there was no NAT.
Signed-off-by: Ulrich Weber <ulrich.weber@sophos.com>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 64f509ce71 upstream.
Clients should not send such packets. By accepting them, we open
up a hole by wich ephemeral ports can be discovered in an off-path
attack.
See: "Reflection scan: an Off-Path Attack on TCP" by Jan Wrobel,
http://arxiv.org/abs/1201.2074
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b1e0d8b70f upstream.
The correct syntax for gcc -x is "gcc -x assembler", not
"gcc -xassembler". Even though the latter happens to work, the former
is what is documented in the manual page and thus what gcc wrappers
such as icecream do expect.
This isn't a cosmetic change. The missing space prevents icecream from
recognizing compilation tasks it can't handle, leading to silent kernel
miscompilations.
Besides me, credits go to Michael Matz and Dirk Mueller for
investigating the miscompilation issue and tracking it down to this
incorrect -x parameter syntax.
Signed-off-by: Jean Delvare <jdelvare@suse.de>
Acked-by: Ingo Molnar <mingo@kernel.org>
Cc: Bernhard Walle <bernhard@bwalle.de>
Cc: Michal Marek <mmarek@suse.cz>
Cc: Ralf Baechle <ralf@linux-mips.org>
Signed-off-by: Michal Marek <mmarek@suse.cz>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
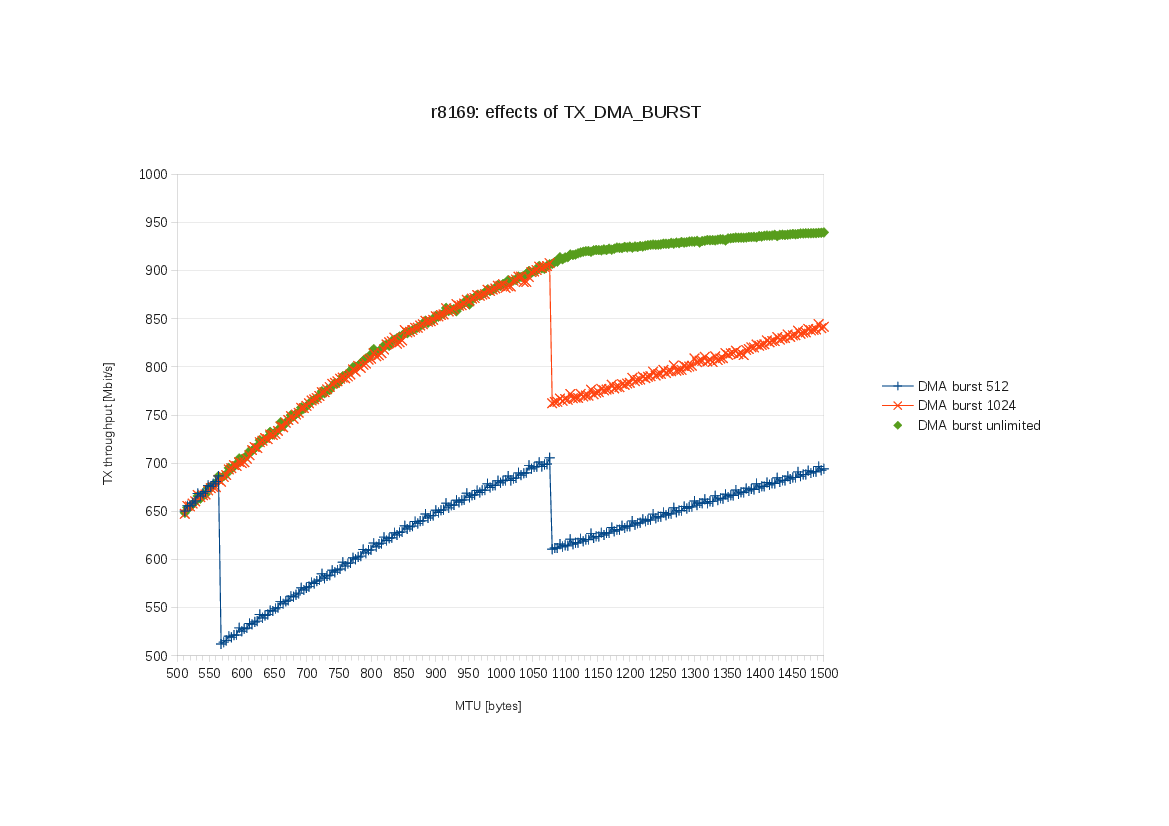
commit aee77e4acc upstream.
The r8169 driver currently limits the DMA burst for TX to 1024 bytes. I have
a box where this prevents the interface from using the gigabit line to its full
potential. This patch solves the problem by setting TX_DMA_BURST to unlimited.
The box has an ASRock B75M motherboard with on-board RTL8168evl/8111evl
(XID 0c900880). TSO is enabled.
I used netperf (TCP_STREAM test) to measure the dependency of TX throughput
on MTU. I did it for three different values of TX_DMA_BURST ('5'=512, '6'=1024,
'7'=unlimited). This chart shows the results:
http://michich.fedorapeople.org/r8169/r8169-effects-of-TX_DMA_BURST.png
Interesting points:
- With the current DMA burst limit (1024):
- at the default MTU=1500 I get only 842 Mbit/s.
- when going from small MTU, the performance rises monotonically with
increasing MTU only up to a peak at MTU=1076 (908 MBit/s). Then there's
a sudden drop to 762 MBit/s from which the throughput rises monotonically
again with further MTU increases.
- With a smaller DMA burst limit (512):
- there's a similar peak at MTU=1076 and another one at MTU=564.
- With unlimited DMA burst:
- at the default MTU=1500 I get nice 940 Mbit/s.
- the throughput rises monotonically with increasing MTU with no strange
peaks.
Notice that the peaks occur at MTU sizes that are multiples of the DMA burst
limit plus 52. Why 52? Because:
20 (IP header) + 20 (TCP header) + 12 (TCP options) = 52
The Realtek-provided r8168 driver (v8.032.00) uses unlimited TX DMA burst too,
except for CFG_METHOD_1 where the TX DMA burst is set to 512 bytes.
CFG_METHOD_1 appears to be the oldest MAC version of "RTL8168B/8111B",
i.e. RTL_GIGA_MAC_VER_11 in r8169. Not sure if this MAC version really needs
the smaller burst limit, or if any other versions have similar requirements.
Signed-off-by: Michal Schmidt <mschmidt@redhat.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit a652208e0b ]
Check (ha->addr == dev->dev_addr) is always true because dev_addr_init()
sets this. Correct the check to behave properly on addr removal.
Signed-off-by: Jiri Pirko <jiri@resnulli.us>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 0c9f79be29 ]
(1<<optname) is undefined behavior in C with a negative optname or
optname larger than 31. In those cases the result of the shift is
not necessarily zero (e.g., on x86).
This patch simplifies the code with a switch statement on optname.
It also allows the compiler to generate better code (e.g., using a
64-bit mask).
Signed-off-by: Xi Wang <xi.wang@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 34fa78b59c upstream.
The sigaddset/sigdelset/sigismember functions that are implemented with
bitfield insn cannot allow the sigset argument to be placed in a data
register since the sigset is wider than 32 bits. Remove the "d"
constraint from the asm statements.
The effect of the bug is that sending RT signals does not work, the signal
number is truncated modulo 32.
Signed-off-by: Andreas Schwab <schwab@linux-m68k.org>
Signed-off-by: Geert Uytterhoeven <geert@linux-m68k.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit d55c4c613f upstream.
When walking page tables we need to make sure that everything
is within bounds of the ASCE limit of the task's address space.
Otherwise we might calculate e.g. a pud pointer which is not
within a pud and dereference it.
So check against TASK_SIZE (which is the ASCE limit) before
walking page tables.
Reviewed-by: Gerald Schaefer <gerald.schaefer@de.ibm.com>
Signed-off-by: Heiko Carstens <heiko.carstens@de.ibm.com>
Signed-off-by: Martin Schwidefsky <schwidefsky@de.ibm.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit a28ad42a4a upstream.
This is a bugfix for a problem with the following symptoms:
1. A power cut happens
2. After reboot, we try to mount UBIFS
3. Mount fails with "No space left on device" error message
UBIFS complains like this:
UBIFS error (pid 28225): grab_empty_leb: could not find an empty LEB
The root cause of this problem is that when we mount, not all LEBs are
categorized. Only those which were read are. However, the
'ubifs_find_free_leb_for_idx()' function assumes that all LEBs were
categorized and 'c->freeable_cnt' is valid, which is a false assumption.
This patch fixes the problem by teaching 'ubifs_find_free_leb_for_idx()'
to always fall back to LPT scanning if no freeable LEBs were found.
This problem was reported by few people in the past, but Brent Taylor
was able to reproduce it and send me a flash image which cannot be mounted,
which made it easy to hunt the bug. Kudos to Brent.
Reported-by: Brent Taylor <motobud@gmail.com>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 445632ad6d upstream.
DAPM shutdown incorrectly uses "list" field of codec struct while
iterating over probed components (codec_dev_list). "list" field
refers to codecs registered in the system, "card_list" field is
used for probed components.
Signed-off-by: Misael Lopez Cruz <misael.lopez@ti.com>
Signed-off-by: Liam Girdwood <lrg@ti.com>
Signed-off-by: Mark Brown <broonie@opensource.wolfsonmicro.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 55c6f4cb6e upstream.
When MCLK is supplied externally and BCLK and LRC are configured as outputs
(codec is master), the PLL values are only calculated correctly on the first
transmission. On subsequent transmissions, at differenct sample rates, the
wrong PLL values are used. Test for f_opclk instead of f_pllout to determine
if the PLL values are needed.
Signed-off-by: Eric Millbrandt <emillbrandt@dekaresearch.com>
Signed-off-by: Mark Brown <broonie@opensource.wolfsonmicro.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 9efade1b3e upstream.
cryptd_queue_worker attempts to prevent simultaneous accesses to crypto
workqueue by cryptd_enqueue_request using preempt_disable/preempt_enable.
However cryptd_enqueue_request might be called from softirq context,
so add local_bh_disable/local_bh_enable to prevent data corruption and
panics.
Bug report at http://marc.info/?l=linux-crypto-vger&m=134858649616319&w=2
v2:
- Disable software interrupts instead of hardware interrupts
Reported-by: Gurucharan Shetty <gurucharan.shetty@gmail.com>
Signed-off-by: Jussi Kivilinna <jussi.kivilinna@mbnet.fi>
Signed-off-by: Herbert Xu <herbert@gondor.apana.org.au>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b0a8cc58e6 upstream.
In kswapd(), set current->reclaim_state to NULL before returning, as
current->reclaim_state holds reference to variable on kswapd()'s stack.
In rare cases, while returning from kswapd() during memory offlining,
__free_slab() and freepages() can access the dangling pointer of
current->reclaim_state.
Signed-off-by: Takamori Yamaguchi <takamori.yamaguchi@jp.sony.com>
Signed-off-by: Aaditya Kumar <aaditya.kumar@ap.sony.com>
Acked-by: David Rientjes <rientjes@google.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 10e44239f6 upstream.
The recent change for USB-audio disconnection race fixes introduced a
mutex deadlock again. There is a circular dependency between
chip->shutdown_rwsem and pcm->open_mutex, depicted like below, when a
device is opened during the disconnection operation:
A. snd_usb_audio_disconnect() ->
card.c::register_mutex ->
chip->shutdown_rwsem (write) ->
snd_card_disconnect() ->
pcm.c::register_mutex ->
pcm->open_mutex
B. snd_pcm_open() ->
pcm->open_mutex ->
snd_usb_pcm_open() ->
chip->shutdown_rwsem (read)
Since the chip->shutdown_rwsem protection in the case A is required
only for turning on the chip->shutdown flag and it doesn't have to be
taken for the whole operation, we can reduce its window in
snd_usb_audio_disconnect().
Reported-by: Jiri Slaby <jslaby@suse.cz>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3e7abe2556 upstream.
When unbinding a device so that I could pass it through to a KVM VM, I
got the lockdep report below. It looks like a legitimate lock
ordering problem:
- domain_context_mapping_one() takes iommu->lock and calls
iommu_support_dev_iotlb(), which takes device_domain_lock (inside
iommu->lock).
- domain_remove_one_dev_info() starts by taking device_domain_lock
then takes iommu->lock inside it (near the end of the function).
So this is the classic AB-BA deadlock. It looks like a safe fix is to
simply release device_domain_lock a bit earlier, since as far as I can
tell, it doesn't protect any of the stuff accessed at the end of
domain_remove_one_dev_info() anyway.
BTW, the use of device_domain_lock looks a bit unsafe to me... it's
at least not obvious to me why we aren't vulnerable to the race below:
iommu_support_dev_iotlb()
domain_remove_dev_info()
lock device_domain_lock
find info
unlock device_domain_lock
lock device_domain_lock
find same info
unlock device_domain_lock
free_devinfo_mem(info)
do stuff with info after it's free
However I don't understand the locking here well enough to know if
this is a real problem, let alone what the best fix is.
Anyway here's the full lockdep output that prompted all of this:
=======================================================
[ INFO: possible circular locking dependency detected ]
2.6.39.1+ #1
-------------------------------------------------------
bash/13954 is trying to acquire lock:
(&(&iommu->lock)->rlock){......}, at: [<ffffffff812f6421>] domain_remove_one_dev_info+0x121/0x230
but task is already holding lock:
(device_domain_lock){-.-...}, at: [<ffffffff812f6508>] domain_remove_one_dev_info+0x208/0x230
which lock already depends on the new lock.
the existing dependency chain (in reverse order) is:
-> #1 (device_domain_lock){-.-...}:
[<ffffffff8109ca9d>] lock_acquire+0x9d/0x130
[<ffffffff81571475>] _raw_spin_lock_irqsave+0x55/0xa0
[<ffffffff812f8350>] domain_context_mapping_one+0x600/0x750
[<ffffffff812f84df>] domain_context_mapping+0x3f/0x120
[<ffffffff812f9175>] iommu_prepare_identity_map+0x1c5/0x1e0
[<ffffffff81ccf1ca>] intel_iommu_init+0x88e/0xb5e
[<ffffffff81cab204>] pci_iommu_init+0x16/0x41
[<ffffffff81002165>] do_one_initcall+0x45/0x190
[<ffffffff81ca3d3f>] kernel_init+0xe3/0x168
[<ffffffff8157ac24>] kernel_thread_helper+0x4/0x10
-> #0 (&(&iommu->lock)->rlock){......}:
[<ffffffff8109bf3e>] __lock_acquire+0x195e/0x1e10
[<ffffffff8109ca9d>] lock_acquire+0x9d/0x130
[<ffffffff81571475>] _raw_spin_lock_irqsave+0x55/0xa0
[<ffffffff812f6421>] domain_remove_one_dev_info+0x121/0x230
[<ffffffff812f8b42>] device_notifier+0x72/0x90
[<ffffffff8157555c>] notifier_call_chain+0x8c/0xc0
[<ffffffff81089768>] __blocking_notifier_call_chain+0x78/0xb0
[<ffffffff810897b6>] blocking_notifier_call_chain+0x16/0x20
[<ffffffff81373a5c>] __device_release_driver+0xbc/0xe0
[<ffffffff81373ccf>] device_release_driver+0x2f/0x50
[<ffffffff81372ee3>] driver_unbind+0xa3/0xc0
[<ffffffff813724ac>] drv_attr_store+0x2c/0x30
[<ffffffff811e4506>] sysfs_write_file+0xe6/0x170
[<ffffffff8117569e>] vfs_write+0xce/0x190
[<ffffffff811759e4>] sys_write+0x54/0xa0
[<ffffffff81579a82>] system_call_fastpath+0x16/0x1b
other info that might help us debug this:
6 locks held by bash/13954:
#0: (&buffer->mutex){+.+.+.}, at: [<ffffffff811e4464>] sysfs_write_file+0x44/0x170
#1: (s_active#3){++++.+}, at: [<ffffffff811e44ed>] sysfs_write_file+0xcd/0x170
#2: (&__lockdep_no_validate__){+.+.+.}, at: [<ffffffff81372edb>] driver_unbind+0x9b/0xc0
#3: (&__lockdep_no_validate__){+.+.+.}, at: [<ffffffff81373cc7>] device_release_driver+0x27/0x50
#4: (&(&priv->bus_notifier)->rwsem){.+.+.+}, at: [<ffffffff8108974f>] __blocking_notifier_call_chain+0x5f/0xb0
#5: (device_domain_lock){-.-...}, at: [<ffffffff812f6508>] domain_remove_one_dev_info+0x208/0x230
stack backtrace:
Pid: 13954, comm: bash Not tainted 2.6.39.1+ #1
Call Trace:
[<ffffffff810993a7>] print_circular_bug+0xf7/0x100
[<ffffffff8109bf3e>] __lock_acquire+0x195e/0x1e10
[<ffffffff810972bd>] ? trace_hardirqs_off+0xd/0x10
[<ffffffff8109d57d>] ? trace_hardirqs_on_caller+0x13d/0x180
[<ffffffff8109ca9d>] lock_acquire+0x9d/0x130
[<ffffffff812f6421>] ? domain_remove_one_dev_info+0x121/0x230
[<ffffffff81571475>] _raw_spin_lock_irqsave+0x55/0xa0
[<ffffffff812f6421>] ? domain_remove_one_dev_info+0x121/0x230
[<ffffffff810972bd>] ? trace_hardirqs_off+0xd/0x10
[<ffffffff812f6421>] domain_remove_one_dev_info+0x121/0x230
[<ffffffff812f8b42>] device_notifier+0x72/0x90
[<ffffffff8157555c>] notifier_call_chain+0x8c/0xc0
[<ffffffff81089768>] __blocking_notifier_call_chain+0x78/0xb0
[<ffffffff810897b6>] blocking_notifier_call_chain+0x16/0x20
[<ffffffff81373a5c>] __device_release_driver+0xbc/0xe0
[<ffffffff81373ccf>] device_release_driver+0x2f/0x50
[<ffffffff81372ee3>] driver_unbind+0xa3/0xc0
[<ffffffff813724ac>] drv_attr_store+0x2c/0x30
[<ffffffff811e4506>] sysfs_write_file+0xe6/0x170
[<ffffffff8117569e>] vfs_write+0xce/0x190
[<ffffffff811759e4>] sys_write+0x54/0xa0
[<ffffffff81579a82>] system_call_fastpath+0x16/0x1b
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
Cc: Steven Rostedt <rostedt@goodmis.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 6ce377afd1 upstream.
Commit 4439647 ("xfs: reset buffer pointers before freeing them") in
3.0-rc1 introduced a regression when recovering log buffers that
wrapped around the end of log. The second part of the log buffer at
the start of the physical log was being read into the header buffer
rather than the data buffer, and hence recovery was seeing garbage
in the data buffer when it got to the region of the log buffer that
was incorrectly read.
Reported-by: Torsten Kaiser <just.for.lkml@googlemail.com>
Signed-off-by: Dave Chinner <dchinner@redhat.com>
Reviewed-by: Christoph Hellwig <hch@lst.de>
Reviewed-by: Mark Tinguely <tinguely@sgi.com>
Signed-off-by: Ben Myers <bpm@sgi.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Fix warning about unused variable introduced by commit e681b66f2e
("USB: mos7840: remove invalid disconnect handling") upstream.
A subsequent fix which removed the disconnect function got rid of the
warning but that one was only backported to v3.6.
Reported-by: Jiri Slaby <jslaby@suse.cz>
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b6e0e543f7 upstream.
Like in the case of native hdmi, which is fixed already in
commit adf00b26d1
Author: Paulo Zanoni <paulo.r.zanoni@intel.com>
Date: Tue Sep 25 13:23:34 2012 -0300
drm/i915: make sure we write all the DIP data bytes
we need to clear the entire sdvo buffer to avoid upsetting the
display.
Since infoframe buffer writing is now a bit more elaborate, extract it
into it's own function. This will be useful if we ever get around to
properly update the ELD for sdvo. Also #define proper names for the
two buffer indexes with fixed usage.
v2: Cite the right commit above, spotted by Paulo Zanoni.
v3: I'm too stupid to paste the right commit.
v4: Ben Hutchings noticed that I've failed to handle an underflow in
my loop logic, breaking it for i >= length + 8. Since I've just lost C
programmer license, use his solution. Also, make the frustrated 0-base
buffer size a notch more clear.
Reported-and-tested-by: Jürg Billeter <j@bitron.ch>
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=25732
Cc: Paulo Zanoni <przanoni@gmail.com>
Cc: Ben Hutchings <ben@decadent.org.uk>
Reviewed-by: Rodrigo Vivi <rodrigo.vivi@gmail.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 81014b9d0b upstream.
At least the worst offenders:
- SDVO specifies that the encoder should compute the ecc. Testing also
shows that we must not send the ecc field, so copy the dip_infoframe
struct to a temporay place and avoid the ecc field. This way the avi
infoframe is exactly 17 bytes long, which agrees with what the spec
mandates as a minimal storage capacity (with the ecc field it would
be 18 bytes).
- Only 17 when sending the avi infoframe. The SDVO spec explicitly
says that sending more data than what the device announces results
in undefined behaviour.
- Add __attribute__((packed)) to the avi and spd infoframes, for
otherwise they're wrongly aligned. Noticed because the avi infoframe
ended up being 18 bytes large instead of 17. We haven't noticed this
yet because we don't use the uint16_t fields yet (which are the only
ones that would be wrongly aligned).
This regression has been introduce by
3c17fe4b8f is the first bad commit
commit 3c17fe4b8f
Author: David Härdeman <david@hardeman.nu>
Date: Fri Sep 24 21:44:32 2010 +0200
i915: enable AVI infoframe for intel_hdmi.c [v4]
Patch tested on my g33 with a sdvo hdmi adaptor.
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=25732
Tested-by: Peter Ross <pross@xvid.org> (G35 SDVO-HDMI)
Reviewed-by: Eugeni Dodonov <eugeni.dodonov@intel.com>
Signed-Off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Cc: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 59fa624519 upstream.
Siddhesh analyzed a failure in the take over of pi futexes in case the
owner died and provided a workaround.
See: http://sourceware.org/bugzilla/show_bug.cgi?id=14076
The detailed problem analysis shows:
Futex F is initialized with PTHREAD_PRIO_INHERIT and
PTHREAD_MUTEX_ROBUST_NP attributes.
T1 lock_futex_pi(F);
T2 lock_futex_pi(F);
--> T2 blocks on the futex and creates pi_state which is associated
to T1.
T1 exits
--> exit_robust_list() runs
--> Futex F userspace value TID field is set to 0 and
FUTEX_OWNER_DIED bit is set.
T3 lock_futex_pi(F);
--> Succeeds due to the check for F's userspace TID field == 0
--> Claims ownership of the futex and sets its own TID into the
userspace TID field of futex F
--> returns to user space
T1 --> exit_pi_state_list()
--> Transfers pi_state to waiter T2 and wakes T2 via
rt_mutex_unlock(&pi_state->mutex)
T2 --> acquires pi_state->mutex and gains real ownership of the
pi_state
--> Claims ownership of the futex and sets its own TID into the
userspace TID field of futex F
--> returns to user space
T3 --> observes inconsistent state
This problem is independent of UP/SMP, preemptible/non preemptible
kernels, or process shared vs. private. The only difference is that
certain configurations are more likely to expose it.
So as Siddhesh correctly analyzed the following check in
futex_lock_pi_atomic() is the culprit:
if (unlikely(ownerdied || !(curval & FUTEX_TID_MASK))) {
We check the userspace value for a TID value of 0 and take over the
futex unconditionally if that's true.
AFAICT this check is there as it is correct for a different corner
case of futexes: the WAITERS bit became stale.
Now the proposed change
- if (unlikely(ownerdied || !(curval & FUTEX_TID_MASK))) {
+ if (unlikely(ownerdied ||
+ !(curval & (FUTEX_TID_MASK | FUTEX_WAITERS)))) {
solves the problem, but it's not obvious why and it wreckages the
"stale WAITERS bit" case.
What happens is, that due to the WAITERS bit being set (T2 is blocked
on that futex) it enforces T3 to go through lookup_pi_state(), which
in the above case returns an existing pi_state and therefor forces T3
to legitimately fight with T2 over the ownership of the pi_state (via
pi_state->mutex). Probelm solved!
Though that does not work for the "WAITERS bit is stale" problem
because if lookup_pi_state() does not find existing pi_state it
returns -ERSCH (due to TID == 0) which causes futex_lock_pi() to
return -ESRCH to user space because the OWNER_DIED bit is not set.
Now there is a different solution to that problem. Do not look at the
user space value at all and enforce a lookup of possibly available
pi_state. If pi_state can be found, then the new incoming locker T3
blocks on that pi_state and legitimately races with T2 to acquire the
rt_mutex and the pi_state and therefor the proper ownership of the
user space futex.
lookup_pi_state() has the correct order of checks. It first tries to
find a pi_state associated with the user space futex and only if that
fails it checks for futex TID value = 0. If no pi_state is available
nothing can create new state at that point because this happens with
the hash bucket lock held.
So the above scenario changes to:
T1 lock_futex_pi(F);
T2 lock_futex_pi(F);
--> T2 blocks on the futex and creates pi_state which is associated
to T1.
T1 exits
--> exit_robust_list() runs
--> Futex F userspace value TID field is set to 0 and
FUTEX_OWNER_DIED bit is set.
T3 lock_futex_pi(F);
--> Finds pi_state and blocks on pi_state->rt_mutex
T1 --> exit_pi_state_list()
--> Transfers pi_state to waiter T2 and wakes it via
rt_mutex_unlock(&pi_state->mutex)
T2 --> acquires pi_state->mutex and gains ownership of the pi_state
--> Claims ownership of the futex and sets its own TID into the
userspace TID field of futex F
--> returns to user space
This covers all gazillion points on which T3 might come in between
T1's exit_robust_list() clearing the TID field and T2 fixing it up. It
also solves the "WAITERS bit stale" problem by forcing the take over.
Another benefit of changing the code this way is that it makes it less
dependent on untrusted user space values and therefor minimizes the
possible wreckage which might be inflicted.
As usual after staring for too long at the futex code my brain hurts
so much that I really want to ditch that whole optimization of
avoiding the syscall for the non contended case for PI futexes and rip
out the maze of corner case handling code. Unfortunately we can't as
user space relies on that existing behaviour, but at least thinking
about it helps me to preserve my mental sanity. Maybe we should
nevertheless :)
Reported-and-tested-by: Siddhesh Poyarekar <siddhesh.poyarekar@gmail.com>
Link: http://lkml.kernel.org/r/alpine.LFD.2.02.1210232138540.2756@ionos
Acked-by: Darren Hart <dvhart@linux.intel.com>
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 60713a0ca7 ]
As documented in RFC4861 (Neighbor Discovery for IP version 6) 7.2.6.,
unsolicited neighbour advertisements should be sent to the all-nodes
multicast address.
Signed-off-by: Hannes Frederic Sowa <hannes@stressinduktion.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 789336360e ]
When creating an L2TPv3 Ethernet session, if register_netdev() should fail for
any reason (for example, automatic naming for "l2tpeth%d" interfaces hits the
32k-interface limit), the netdev is freed in the error path. However, the
l2tp_eth_sess structure's dev pointer is left uncleared, and this results in
l2tp_eth_delete() then attempting to unregister the same netdev later in the
session teardown. This results in an oops.
To avoid this, clear the session dev pointer in the error path.
Signed-off-by: Tom Parkin <tparkin@katalix.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
{kind=link}