commit a4ac9fea01 upstream.
During debug of one SRIOV enabled hotplug device, we found found that
add_size is not passed properly.
The device has devices under two level bridges:
+-[0000:80]-+-00.0-[81-8f]--
| +-01.0-[90-9f]--
| +-02.0-[a0-af]----00.0-[a1-a3]--+-02.0-[a2]--+-00.0 Oracle Corporation Device
| | \-03.0-[a3]--+-00.0 Oracle Corporation Device
Which means later the parent bridge will not try to add a big enough range:
[ 557.455077] pci 0000:a0:00.0: BAR 14: assigned [mem 0xf9000000-0xf93fffff]
[ 557.461974] pci 0000:a0:00.0: BAR 15: assigned [mem 0xf6000000-0xf61fffff pref]
[ 557.469340] pci 0000:a1:02.0: BAR 14: assigned [mem 0xf9000000-0xf91fffff]
[ 557.476231] pci 0000:a1:02.0: BAR 15: assigned [mem 0xf6000000-0xf60fffff pref]
[ 557.483582] pci 0000:a1:03.0: BAR 14: assigned [mem 0xf9200000-0xf93fffff]
[ 557.490468] pci 0000:a1:03.0: BAR 15: assigned [mem 0xf6100000-0xf61fffff pref]
[ 557.497833] pci 0000:a1:03.0: BAR 14: can't assign mem (size 0x200000)
[ 557.504378] pci 0000:a1:03.0: failed to add optional resources res=[mem 0xf9200000-0xf93fffff]
[ 557.513026] pci 0000:a1:02.0: BAR 14: can't assign mem (size 0x200000)
[ 557.519578] pci 0000:a1:02.0: failed to add optional resources res=[mem 0xf9000000-0xf91fffff]
It turns out we did not calculate size1 properly.
static resource_size_t calculate_memsize(resource_size_t size,
resource_size_t min_size,
resource_size_t size1,
resource_size_t old_size,
resource_size_t align)
{
if (size < min_size)
size = min_size;
if (old_size == 1 )
old_size = 0;
if (size < old_size)
size = old_size;
size = ALIGN(size + size1, align);
return size;
}
We should not pass add_size with min_size in calculate_memsize since
that will make add_size not contribute final add_size.
So just pass add_size with size1 to calculate_memsize().
With this change, we should have chance to remove extra addon in
pci_reassign_resource.
Signed-off-by: Yinghai Lu <yinghai@kernel.org>
Signed-off-by: Jesse Barnes <jbarnes@virtuousgeek.org>
Cc: Andrew Worsley <amworsley@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 2bbc694227 upstream.
Currently pci-bridges are allocated enough resources to satisfy their immediate
requirements. Any additional resource-requests fail if additional free space,
contiguous to the one already allocated, is not available. This behavior is not
reasonable since sufficient contiguous resources, that can satisfy the request,
are available at a different location.
This patch provides the ability to expand and relocate a allocated resource.
v2: Changelog: Fixed size calculation in pci_reassign_resource()
v3: Changelog : Split this patch. The resource.c changes are already
upstream. All the pci driver changes are in here.
Signed-off-by: Ram Pai <linuxram@us.ibm.com>
Signed-off-by: Jesse Barnes <jbarnes@virtuousgeek.org>
Cc: Andrew Worsley <amworsley@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit a9193983f4 upstream.
The overlay on the i830M has a peculiar failure mode: It works the
first time around after boot-up, but consistenly hangs the second time
it's used.
Chris Wilson has dug out a nice errata:
"1.5.12 Clock Gating Disable for Display Register
Address Offset: 06200h–06203h
"Bit 3
Ovrunit Clock Gating Disable.
0 = Clock gating controlled by unit enabling logic
1 = Disable clock gating function
DevALM Errata ALM049: Overlay Clock Gating Must be Disabled: Overlay
& L2 Cache clock gating must be disabled in order to prevent device
hangs when turning off overlay.SW must turn off Ovrunit clock gating
(6200h) and L2 Cache clock gating (C8h)."
Now I've nowhere found that 0xc8 register and hence couldn't apply the
l2 cache workaround. But I've remembered that part of the magic that
the OVERLAY_ON/OFF commands are supposed to do is to rearrange cache
allocations so that the overlay scaler has some scratch space.
And while pondering how that could explain the hang the 2nd time we
enable the overlay, I've remembered that the old ums overlay code did
_not_ issue the OVERLAY_OFF cmd.
And indeed, disabling the OFF cmd results in the overlay working
flawlessly, so I guess we can workaround the lack of the above
workaround by simply never disabling the overlay engine once it's
enabled.
Note that we have the first part of the above w/a already implemented
in i830_init_clock_gating - leave that as-is to avoid surprises.
v2: Add a comment in the code.
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=47827
Tested-by: Rhys <rhyspuk@gmail.com>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2:
- Adjust context
- s/intel_ring_emit(ring, /OUT_RING(/]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 0658a3366d upstream.
The use of kfree(serial) in error cases of usb_serial_probe
was invalid - usb_serial structure allocated in create_serial()
gets reference of usb_device that needs to be put, so we need
to use usb_serial_put() instead of simple kfree().
Signed-off-by: Jan Safrata <jan.nikitenko@gmail.com>
Acked-by: Johan Hovold <jhovold@gmail.com>
Cc: Richard Retanubun <richardretanubun@ruggedcom.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit aee77e4acc upstream.
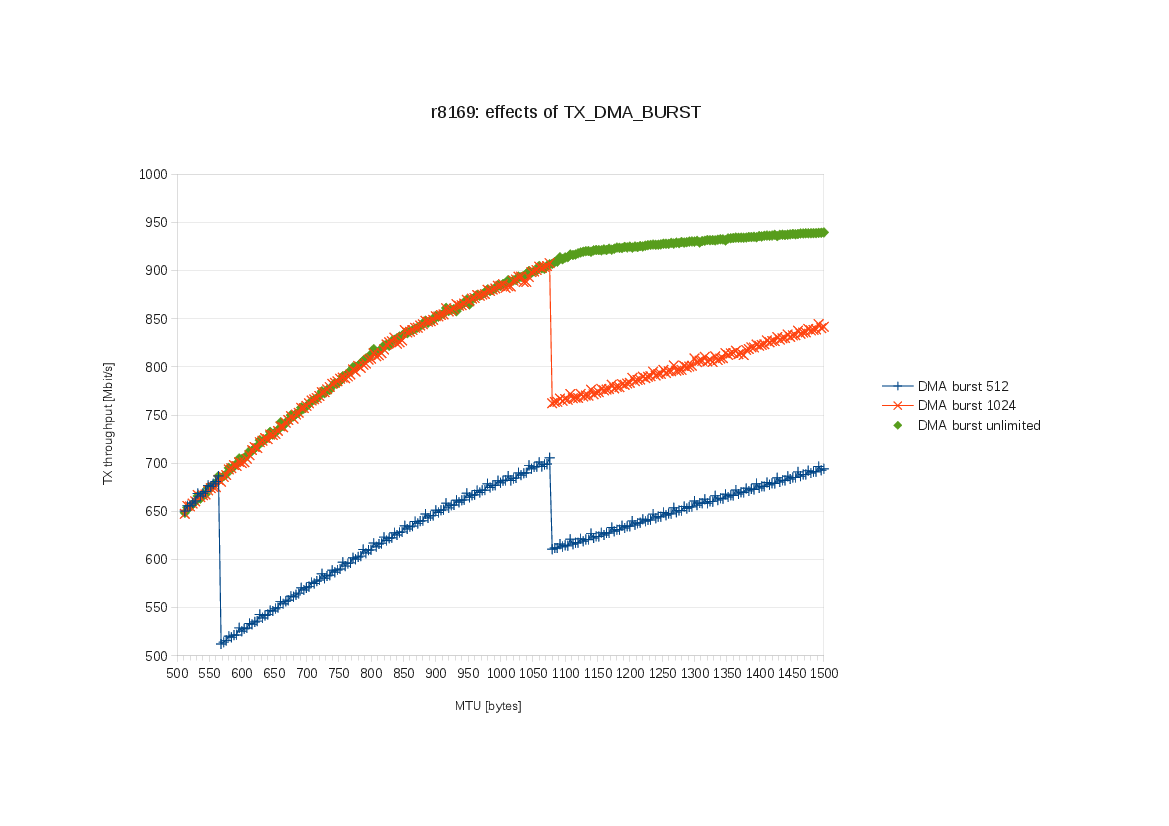
The r8169 driver currently limits the DMA burst for TX to 1024 bytes. I have
a box where this prevents the interface from using the gigabit line to its full
potential. This patch solves the problem by setting TX_DMA_BURST to unlimited.
The box has an ASRock B75M motherboard with on-board RTL8168evl/8111evl
(XID 0c900880). TSO is enabled.
I used netperf (TCP_STREAM test) to measure the dependency of TX throughput
on MTU. I did it for three different values of TX_DMA_BURST ('5'=512, '6'=1024,
'7'=unlimited). This chart shows the results:
http://michich.fedorapeople.org/r8169/r8169-effects-of-TX_DMA_BURST.png
Interesting points:
- With the current DMA burst limit (1024):
- at the default MTU=1500 I get only 842 Mbit/s.
- when going from small MTU, the performance rises monotonically with
increasing MTU only up to a peak at MTU=1076 (908 MBit/s). Then there's
a sudden drop to 762 MBit/s from which the throughput rises monotonically
again with further MTU increases.
- With a smaller DMA burst limit (512):
- there's a similar peak at MTU=1076 and another one at MTU=564.
- With unlimited DMA burst:
- at the default MTU=1500 I get nice 940 Mbit/s.
- the throughput rises monotonically with increasing MTU with no strange
peaks.
Notice that the peaks occur at MTU sizes that are multiples of the DMA burst
limit plus 52. Why 52? Because:
20 (IP header) + 20 (TCP header) + 12 (TCP options) = 52
The Realtek-provided r8168 driver (v8.032.00) uses unlimited TX DMA burst too,
except for CFG_METHOD_1 where the TX DMA burst is set to 512 bytes.
CFG_METHOD_1 appears to be the oldest MAC version of "RTL8168B/8111B",
i.e. RTL_GIGA_MAC_VER_11 in r8169. Not sure if this MAC version really needs
the smaller burst limit, or if any other versions have similar requirements.
Signed-off-by: Michal Schmidt <mschmidt@redhat.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3e7abe2556 upstream.
When unbinding a device so that I could pass it through to a KVM VM, I
got the lockdep report below. It looks like a legitimate lock
ordering problem:
- domain_context_mapping_one() takes iommu->lock and calls
iommu_support_dev_iotlb(), which takes device_domain_lock (inside
iommu->lock).
- domain_remove_one_dev_info() starts by taking device_domain_lock
then takes iommu->lock inside it (near the end of the function).
So this is the classic AB-BA deadlock. It looks like a safe fix is to
simply release device_domain_lock a bit earlier, since as far as I can
tell, it doesn't protect any of the stuff accessed at the end of
domain_remove_one_dev_info() anyway.
BTW, the use of device_domain_lock looks a bit unsafe to me... it's
at least not obvious to me why we aren't vulnerable to the race below:
iommu_support_dev_iotlb()
domain_remove_dev_info()
lock device_domain_lock
find info
unlock device_domain_lock
lock device_domain_lock
find same info
unlock device_domain_lock
free_devinfo_mem(info)
do stuff with info after it's free
However I don't understand the locking here well enough to know if
this is a real problem, let alone what the best fix is.
Anyway here's the full lockdep output that prompted all of this:
=======================================================
[ INFO: possible circular locking dependency detected ]
2.6.39.1+ #1
-------------------------------------------------------
bash/13954 is trying to acquire lock:
(&(&iommu->lock)->rlock){......}, at: [<ffffffff812f6421>] domain_remove_one_dev_info+0x121/0x230
but task is already holding lock:
(device_domain_lock){-.-...}, at: [<ffffffff812f6508>] domain_remove_one_dev_info+0x208/0x230
which lock already depends on the new lock.
the existing dependency chain (in reverse order) is:
-> #1 (device_domain_lock){-.-...}:
[<ffffffff8109ca9d>] lock_acquire+0x9d/0x130
[<ffffffff81571475>] _raw_spin_lock_irqsave+0x55/0xa0
[<ffffffff812f8350>] domain_context_mapping_one+0x600/0x750
[<ffffffff812f84df>] domain_context_mapping+0x3f/0x120
[<ffffffff812f9175>] iommu_prepare_identity_map+0x1c5/0x1e0
[<ffffffff81ccf1ca>] intel_iommu_init+0x88e/0xb5e
[<ffffffff81cab204>] pci_iommu_init+0x16/0x41
[<ffffffff81002165>] do_one_initcall+0x45/0x190
[<ffffffff81ca3d3f>] kernel_init+0xe3/0x168
[<ffffffff8157ac24>] kernel_thread_helper+0x4/0x10
-> #0 (&(&iommu->lock)->rlock){......}:
[<ffffffff8109bf3e>] __lock_acquire+0x195e/0x1e10
[<ffffffff8109ca9d>] lock_acquire+0x9d/0x130
[<ffffffff81571475>] _raw_spin_lock_irqsave+0x55/0xa0
[<ffffffff812f6421>] domain_remove_one_dev_info+0x121/0x230
[<ffffffff812f8b42>] device_notifier+0x72/0x90
[<ffffffff8157555c>] notifier_call_chain+0x8c/0xc0
[<ffffffff81089768>] __blocking_notifier_call_chain+0x78/0xb0
[<ffffffff810897b6>] blocking_notifier_call_chain+0x16/0x20
[<ffffffff81373a5c>] __device_release_driver+0xbc/0xe0
[<ffffffff81373ccf>] device_release_driver+0x2f/0x50
[<ffffffff81372ee3>] driver_unbind+0xa3/0xc0
[<ffffffff813724ac>] drv_attr_store+0x2c/0x30
[<ffffffff811e4506>] sysfs_write_file+0xe6/0x170
[<ffffffff8117569e>] vfs_write+0xce/0x190
[<ffffffff811759e4>] sys_write+0x54/0xa0
[<ffffffff81579a82>] system_call_fastpath+0x16/0x1b
other info that might help us debug this:
6 locks held by bash/13954:
#0: (&buffer->mutex){+.+.+.}, at: [<ffffffff811e4464>] sysfs_write_file+0x44/0x170
#1: (s_active#3){++++.+}, at: [<ffffffff811e44ed>] sysfs_write_file+0xcd/0x170
#2: (&__lockdep_no_validate__){+.+.+.}, at: [<ffffffff81372edb>] driver_unbind+0x9b/0xc0
#3: (&__lockdep_no_validate__){+.+.+.}, at: [<ffffffff81373cc7>] device_release_driver+0x27/0x50
#4: (&(&priv->bus_notifier)->rwsem){.+.+.+}, at: [<ffffffff8108974f>] __blocking_notifier_call_chain+0x5f/0xb0
#5: (device_domain_lock){-.-...}, at: [<ffffffff812f6508>] domain_remove_one_dev_info+0x208/0x230
stack backtrace:
Pid: 13954, comm: bash Not tainted 2.6.39.1+ #1
Call Trace:
[<ffffffff810993a7>] print_circular_bug+0xf7/0x100
[<ffffffff8109bf3e>] __lock_acquire+0x195e/0x1e10
[<ffffffff810972bd>] ? trace_hardirqs_off+0xd/0x10
[<ffffffff8109d57d>] ? trace_hardirqs_on_caller+0x13d/0x180
[<ffffffff8109ca9d>] lock_acquire+0x9d/0x130
[<ffffffff812f6421>] ? domain_remove_one_dev_info+0x121/0x230
[<ffffffff81571475>] _raw_spin_lock_irqsave+0x55/0xa0
[<ffffffff812f6421>] ? domain_remove_one_dev_info+0x121/0x230
[<ffffffff810972bd>] ? trace_hardirqs_off+0xd/0x10
[<ffffffff812f6421>] domain_remove_one_dev_info+0x121/0x230
[<ffffffff812f8b42>] device_notifier+0x72/0x90
[<ffffffff8157555c>] notifier_call_chain+0x8c/0xc0
[<ffffffff81089768>] __blocking_notifier_call_chain+0x78/0xb0
[<ffffffff810897b6>] blocking_notifier_call_chain+0x16/0x20
[<ffffffff81373a5c>] __device_release_driver+0xbc/0xe0
[<ffffffff81373ccf>] device_release_driver+0x2f/0x50
[<ffffffff81372ee3>] driver_unbind+0xa3/0xc0
[<ffffffff813724ac>] drv_attr_store+0x2c/0x30
[<ffffffff811e4506>] sysfs_write_file+0xe6/0x170
[<ffffffff8117569e>] vfs_write+0xce/0x190
[<ffffffff811759e4>] sys_write+0x54/0xa0
[<ffffffff81579a82>] system_call_fastpath+0x16/0x1b
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
Cc: Steven Rostedt <rostedt@goodmis.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Fix warning about unused variable introduced by commit e681b66f2e
("USB: mos7840: remove invalid disconnect handling") upstream.
A subsequent fix which removed the disconnect function got rid of the
warning but that one was only backported to v3.6.
Reported-by: Jiri Slaby <jslaby@suse.cz>
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b6e0e543f7 upstream.
Like in the case of native hdmi, which is fixed already in
commit adf00b26d1
Author: Paulo Zanoni <paulo.r.zanoni@intel.com>
Date: Tue Sep 25 13:23:34 2012 -0300
drm/i915: make sure we write all the DIP data bytes
we need to clear the entire sdvo buffer to avoid upsetting the
display.
Since infoframe buffer writing is now a bit more elaborate, extract it
into it's own function. This will be useful if we ever get around to
properly update the ELD for sdvo. Also #define proper names for the
two buffer indexes with fixed usage.
v2: Cite the right commit above, spotted by Paulo Zanoni.
v3: I'm too stupid to paste the right commit.
v4: Ben Hutchings noticed that I've failed to handle an underflow in
my loop logic, breaking it for i >= length + 8. Since I've just lost C
programmer license, use his solution. Also, make the frustrated 0-base
buffer size a notch more clear.
Reported-and-tested-by: Jürg Billeter <j@bitron.ch>
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=25732
Cc: Paulo Zanoni <przanoni@gmail.com>
Cc: Ben Hutchings <ben@decadent.org.uk>
Reviewed-by: Rodrigo Vivi <rodrigo.vivi@gmail.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 81014b9d0b upstream.
At least the worst offenders:
- SDVO specifies that the encoder should compute the ecc. Testing also
shows that we must not send the ecc field, so copy the dip_infoframe
struct to a temporay place and avoid the ecc field. This way the avi
infoframe is exactly 17 bytes long, which agrees with what the spec
mandates as a minimal storage capacity (with the ecc field it would
be 18 bytes).
- Only 17 when sending the avi infoframe. The SDVO spec explicitly
says that sending more data than what the device announces results
in undefined behaviour.
- Add __attribute__((packed)) to the avi and spd infoframes, for
otherwise they're wrongly aligned. Noticed because the avi infoframe
ended up being 18 bytes large instead of 17. We haven't noticed this
yet because we don't use the uint16_t fields yet (which are the only
ones that would be wrongly aligned).
This regression has been introduce by
3c17fe4b8f is the first bad commit
commit 3c17fe4b8f
Author: David Härdeman <david@hardeman.nu>
Date: Fri Sep 24 21:44:32 2010 +0200
i915: enable AVI infoframe for intel_hdmi.c [v4]
Patch tested on my g33 with a sdvo hdmi adaptor.
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=25732
Tested-by: Peter Ross <pross@xvid.org> (G35 SDVO-HDMI)
Reviewed-by: Eugeni Dodonov <eugeni.dodonov@intel.com>
Signed-Off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Cc: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 39707c2a3b ]
Driver anchors the tx urbs and defers the urb submission if
a transmit request comes when the interface is suspended.
Anchoring urb increments the urb reference count. These
deferred urbs are later accessed by calling usb_get_from_anchor()
for submission during interface resume. usb_get_from_anchor()
unanchors the urb but urb reference count remains same.
This causes the urb reference count to remain non-zero
after usb_free_urb() gets called and urb never gets freed.
Hence call usb_put_urb() after anchoring the urb to properly
balance the reference count for these deferred urbs. Also,
unanchor these deferred urbs during disconnect, to free them
up.
Signed-off-by: Hemant Kumar <hemantk@codeaurora.org>
Acked-by: Oliver Neukum <oneukum@suse.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3300fb4f88 upstream.
Don't assume bank 0 is selected at device probe time. This may not be
the case. Force bank selection at first register access to guarantee
that we read the right registers upon driver loading.
Signed-off-by: Jean Delvare <khali@linux-fr.org>
Reviewed-by: Guenter Roeck <linux@roeck-us.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 0d0f9dfb31 upstream.
If the call to core_dev_release_virtual_lun0() fails, then nothing
sets ret to anything other than 0, so even though everything is
torn down and freed, target_core_init_configfs() will seem to succeed
and the module will be loaded. Fix this by passing the return value
on up the chain.
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit bf7e1abe43 upstream.
Some hardware has correct (!= 0xff) value of tssi_bounds[4] in the
EEPROM, but step is equal to 0xff. This results on ridiculous delta
calculations and completely broke TX power settings.
Reported-and-tested-by: Pavel Lucik <pavel.lucik@gmail.com>
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Acked-by: Ivo van Doorn <IvDoorn@gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 8c6e30936a upstream.
bf->bf_next is only while buffers are chained as part of an A-MPDU
in the tx queue. When a tid queue is flushed (e.g. on tearing down
an aggregation session), frames can be enqueued again as normal
transmission, without bf_next being cleared. This can lead to the
old pointer being dereferenced again later.
This patch might fix crashes and "Failed to stop TX DMA!" messages.
Signed-off-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit f6365201d8 upstream.
The X86_32-only disable_hlt/enable_hlt mechanism was used by the
32-bit floppy driver. Its effect was to replace the use of the
HLT instruction inside default_idle() with cpu_relax() - essentially
it turned off the use of HLT.
This workaround was commented in the code as:
"disable hlt during certain critical i/o operations"
"This halt magic was a workaround for ancient floppy DMA
wreckage. It should be safe to remove."
H. Peter Anvin additionally adds:
"To the best of my knowledge, no-hlt only existed because of
flaky power distributions on 386/486 systems which were sold to
run DOS. Since DOS did no power management of any kind,
including HLT, the power draw was fairly uniform; when exposed
to the much hhigher noise levels you got when Linux used HLT
caused some of these systems to fail.
They were by far in the minority even back then."
Alan Cox further says:
"Also for the Cyrix 5510 which tended to go castors up if a HLT
occurred during a DMA cycle and on a few other boxes HLT during
DMA tended to go astray.
Do we care ? I doubt it. The 5510 was pretty obscure, the 5520
fixed it, the 5530 is probably the oldest still in any kind of
use."
So, let's finally drop this.
Signed-off-by: Len Brown <len.brown@intel.com>
Signed-off-by: Josh Boyer <jwboyer@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Acked-by: "H. Peter Anvin" <hpa@zytor.com>
Acked-by: Alan Cox <alan@lxorguk.ukuu.org.uk>
Cc: Stephen Hemminger <shemminger@vyatta.com
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Link: http://lkml.kernel.org/n/tip-3rhk9bzf0x9rljkv488tloib@git.kernel.org
[ If anyone cares then alternative instruction patching could be
used to replace HLT with a one-byte NOP instruction. Much simpler. ]
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit aaeb61a97b upstream.
`pc236_detach()` is called by the comedi core if it attempted to attach
a device and failed. `pc236_detach()` calls `pc236_intr_disable()` if
the comedi device private data pointer (`devpriv`) is non-null. This
test is insufficient as `pc236_intr_disable()` accesses hardware
registers and the attach routine may have failed before it has saved
their I/O base addresses.
Fix it by checking `dev->iobase` is non-zero before calling
`pc236_intr_disable()` as that means the I/O base addresses have been
saved and the hardware registers can be accessed. It also implies the
comedi device private data pointer is valid, so there is no need to
check it.
Signed-off-by: Ian Abbott <abbotti@mev.co.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 910a578f7e upstream.
We copy head count to a 16 bit field, this works by chance on LE but on
BE guest gets 0. Fix it up.
Signed-off-by: Michael S. Tsirkin <mst@redhat.com>
Tested-by: Alexander Graf <agraf@suse.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 43a09f7fb0 upstream.
The command cancellation code doesn't check whether find_trb_seg()
couldn't find the segment that contains the TRB to be canceled. This
could cause a NULL pointer deference later in the function when next_trb
is called. It's unlikely to happen unless something is wrong with the
command ring pointers, so add some debugging in case it happens.
This patch should be backported to stable kernels as old as 3.0, that
contain the commit b63f4053cc "xHCI:
handle command after aborting the command ring".
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit e681b66f2e upstream.
Remove private zombie flag used to signal disconnect and to prevent
control urb from being submitted from interrupt urb completion handler.
The control urb will not be re-submitted as both the control urb and the
interrupt urb is killed on disconnect.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 28c3ae9a8c upstream.
The private int_urb is never allocated so the submission from the
control completion handler will always fail. Remove this odd piece of
broken code.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3eb55cc4ed upstream.
The driver set the usb-serial port pointers to NULL on errors in attach,
effectively preventing usb-serial core from decrementing the port ref
counters and releasing the port devices and associated data.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 084817d793 upstream.
Move interface data allocation to attach so that it is deallocated on
errors in usb-serial probe.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit f7bc505166 upstream.
I found a memory leak in sierra_release() (well sierra_probe() I guess)
that looses 8 bytes each time the driver releases a device.
Signed-off-by: Len Sorensen <lsorense@csclub.uwaterloo.ca>
Acked-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit ea0dbebffe upstream.
Make sure to allocate the control-message buffer dynamically as some
platforms cannot do DMA from stack.
Note that only the first byte of the old buffer was used.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit c323dc023b upstream.
BIOS vendors keep changing the BIOS versions. Only match the beginning
of the string to match all Lucid tablets with board name M11JB.
Signed-off-by: Anisse Astier <anisse@astier.eu>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b63f4053cc upstream.
According to xHCI spec section 4.6.1.1 and section 4.6.1.2,
after aborting a command on the command ring, xHC will
generate a command completion event with its completion
code set to Command Ring Stopped at least. If a command is
currently executing at the time of aborting a command, xHC
also generate a command completion event with its completion
code set to Command Abort. When the command ring is stopped,
software may remove, add, or rearrage Command Descriptors.
To cancel a command, software will initialize a command
descriptor for the cancel command, and add it into a
cancel_cmd_list of xhci. When the command ring is stopped,
software will find the command trbs described by command
descriptors in cancel_cmd_list and modify it to No Op
command. If software can't find the matched trbs, we can
think it had been finished.
This patch should be backported to kernels as old as 3.0, that contain
the commit 7ed603ecf8 "xhci: Add an
assertion to check for virt_dev=0 bug." That commit papers over a NULL
pointer dereference, and this patch fixes the underlying issue that
caused the NULL pointer dereference.
Note from Sarah: The TRB_TYPE_LINK_LE32 macro is not in the 3.0 stable
kernel, so I added it to this patch.
Signed-off-by: Elric Fu <elricfu1@gmail.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Tested-by: Miroslav Sabljic <miroslav.sabljic@avl.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 6e4468b9a0 upstream.
The patch is used to cancel command when the command isn't
acknowledged and a timeout occurs.
This patch should be backported to kernels as old as 3.0, that contain
the commit 7ed603ecf8 "xhci: Add an
assertion to check for virt_dev=0 bug." That commit papers over a NULL
pointer dereference, and this patch fixes the underlying issue that
caused the NULL pointer dereference.
Signed-off-by: Elric Fu <elricfu1@gmail.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Tested-by: Miroslav Sabljic <miroslav.sabljic@avl.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b92cc66c04 upstream.
Software have to abort command ring and cancel command
when a command is failed or hang. Otherwise, the command
ring will hang up and can't handle the others. An example
of a command that may hang is the Address Device Command,
because waiting for a SET_ADDRESS request to be acknowledged
by a USB device is outside of the xHC's ability to control.
To cancel a command, software will initialize a command
descriptor for the cancel command, and add it into a
cancel_cmd_list of xhci.
Sarah: Fixed missing newline on "Have the command ring been stopped?"
debugging statement.
This patch should be backported to kernels as old as 3.0, that contain
the commit 7ed603ecf8 "xhci: Add an
assertion to check for virt_dev=0 bug." That commit papers over a NULL
pointer dereference, and this patch fixes the underlying issue that
caused the NULL pointer dereference.
Signed-off-by: Elric Fu <elricfu1@gmail.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Tested-by: Miroslav Sabljic <miroslav.sabljic@avl.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit c181bc5b5d upstream.
Adding cmd_ring_state for command ring. It helps to verify
the current command ring state for controlling the command
ring operations.
This patch should be backported to kernels as old as 3.0. The commit
7ed603ecf8 "xhci: Add an assertion to
check for virt_dev=0 bug." papers over the NULL pointer dereference that
I now believe is related to a timed out Set Address command. This (and
the four patches that follow it) contain the real fix that also allows
VIA USB 3.0 hubs to consistently re-enumerate during the plug/unplug
stress tests.
Signed-off-by: Elric Fu <elricfu1@gmail.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Tested-by: Miroslav Sabljic <miroslav.sabljic@avl.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3bcf603f6d upstream.
On CougarPoint and PantherPoint PCH chips, the timing generator may fail
to start after DP training completes. This is due to a bug in the
FDI autotraining detect logic (which will stall the timing generator and
re-enable it once training completes), so disable it to avoid silent DP
mode setting failures.
Signed-off-by: Jesse Barnes <jbarnes@virtuousgeek.org>
Signed-off-by: Keith Packard <keithp@keithp.com>
Signed-off-by: Timo Aaltonen <timo.aaltonen@canonical.com>
{kind=link}